Elastic search is a great search engine to enhance the search capabilities of your product. It is open-source and provides a RESTful interface for your application to interact with. You can read more about it online, as the internet is full of great articles going in-depth of various aspects of it. Most of the setup was smooth and we did not really have to work hard to understand the construction of queries. NEST fluent API just makes things super easy.
I want to share a couple of things that we considered quite early on and it worked quite well for us.
- ReIndexing (with zero downtime)
- Integration testing (including Elastic Search)
ReIndexing:
Out of box Elastic search gives an ability to reindex on the server. Because it does it on the server, it is quite efficient in many ways. All you need is the source and the destination index names. Sounds simple and it is in fact quite simple.
- Create new Index
- ReIndex by copying from existing to new Index
- Point the Alias to new Index.
But as always, out of the box does most of it, but it is just that last 10% you need to suit your needs make you pull your hair. Our needs were very specific:
- No downtime
- A fully automated process
- Complete automation of testing
We decided to track the indexed document schema version. So if there is breaking change in the document schema, we just need to increment the version and deploy. Our startup code does the rest of plumbing.
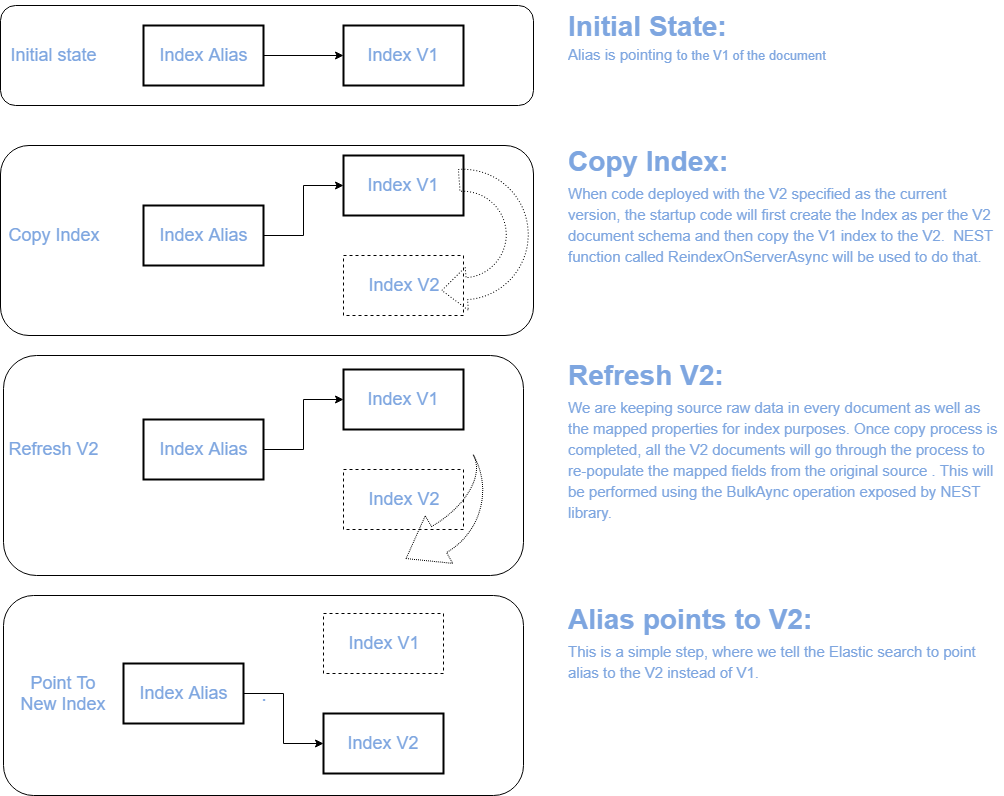
As startup code would do something like following:
var response = await elasticClient.IndexExists(_settings.CurrentIndexName);
if (!response.Exists)
{
await elasticClient.CreateIndexAsync(indexName, (c) => CreateIndexDescriptor(c)
.Aliases(al => al.Alias(alias))
}
await client.ReindexOnServerAsync(request => request
.WaitForCompletion(false)
.Source(sel => sel.Index(Indices.Index((IndexName)currentIndexName)))
.Destination(dst => dst
.Index((IndexName)newIndexName)
.VersionType(VersionType.ExternalGte)
));
// query
var results = client.Search(s => s
.Index(_settings.ElasticIndexAlias)
.From(0)
.Size(1000)
.Source(x => x.Includes(i => i.Field(f => f.RawSourceV1)))
.SearchType(SearchType.QueryThenFetch)
.Scroll("20m"));
var total = results.Total;
var count = 0;
while (results.Documents.Any())
{
var retry = false;
var retrycount = 0;
do
{
var bulkUpdateResponse = await client.BulkAsync(descriptor =>
descriptor.Index(newIndexName)
.IndexMany(results.Documents.Select(MapFunc), (indexDescriptor, model) =>
indexDescriptor.Version(model.Version)
.VersionType(VersionType.ExternalGte)));
count = count + results.Documents.Count;
if (bulkUpdateResponse.IsValid) continue;
if (retrycount < 3 && bulkUpdateResponse.ServerError?.Error?.Type ==
"cluster_block_exception")
{
retrycount++;
retry = true;
await Task.Delay(new TimeSpan(0, 0, 0, 10));
}
} while (retry && retrycount < 3);
}
Integration testing:
We have quite advanced use of the Elastic search queries as well as complex ranking. Our code was highly relying on the elastic search so any unit test mocking would be of low value. So we decided to go for integration test that goes all the way to elastic search. Initially, we were planning to talk to the deployed elastic search cluster with each run using a “GUID” for the index and alias names. That was requiring bit complex setup for local machines as well as the automated builds.
Luckily there is a nuget package to the rescue, it is called elasticsearch-inside. This little gem provides the fully embedded elastic search in a DLL. With this, you can start an elastic search instance at startup and dismantle that at the dispose. It is super easy to set up, you just need to use the ElasticSearchInside.ElasticSearch instance. The only thing we have to manage is the lifespan of its instance to minimise the overhead of bootstrapping elastic search for every test. We managed that using xunit collection fixture.
Investing time early on these couple of goodies turned out to be a real enabler for us to deploy with confidence, even when it is a breaking change to the elastic document. I hope someone find these tricks helpful.

Leave a comment