TL;DR: Use "Events as a Data Product" of your BoundedContext in the Data-Mesh by applying 'Data on the outside' thinking using KAPPA architecture.
As data is getting bigger, it is important to make it better. With the introduction of flexible cloud resources, our systems can now accumulate vast amounts of data at remarkably low expenses, thereby enabling them to generate substantial value from this information.
The journey of persisting our data has come a long way from data warehouses to data lakes and now evolving into data mesh architecture. This architecture leverages the domain boundaries in the data space to avoid issues with the monolithic nature of the data lake, as explained in the data mesh architecture paper. Following are the 4 principles Zhamak Dehghani put forward when coined this concept in 2019.
1) domain-oriented decentralized data ownership and architecture,
2) data as a product
3) self-serve data infrastructure as a platform
4) federated computational governance.
Domain-driven design has given us an excellent guide to tackling complexity by keeping the domain concepts at the core of our designs. By defining ubiquitous language we demarcate context boundaries and divide the system into well-defined bounded contexts. Typically, we create a small world of aggregates and entities within these bounded contexts to implement business logic. Being part of a cohesive whole, these bounded contexts need to communicate with each other as well as external systems including cross-cutting concerns (reporting, analytics, etc.). The concept of data as a product in the data mesh architecture is advocating to protect domain boundaries while still unlocking data value at scale.
With yet another channel of data consumers, the key question is how we make this data available consistently without overloading the team with multiple data models of their domain. In a very basic form, API and Events are the primary interfaces to a domain model. Structure of our data we share via these interfaces can be considered as a basic form or building blocks of our data products. A resource in a RESTful API represents a piece of data, and how it’s structured and presented to the user can turn it into a valuable data product. In this post, I will discuss how events can leverage the same structure and provide an efficient mechanism to participate in the Data Mesh.

In a typical data-mesh architecture you will expose your data for bulk/batch consumption by creating views on the data in BigQuery type of databases. Though it may not look like too much work in some of the use cases, it will still be yet another contract/interface your system has to support. Even though the interface is a SQL view or a pipeline to extract in a custom shape, it will still be a contract for a source system to build and maintain, just like strongly typed interfaces (e.g.Protocol Buffer) for APIs and Events. In fact, the interfaces for API and Event-based are quite mature and they have well-defined standards for versioning and managing breaking changes. Data extraction and SQL-based contracts would also be subject to the same expectations from the consumers but finding/defining standards in this area could be harder than it looks. Moreover, this will also lead to duplicate logic outside our domain code to translate our data into a data product in a pipeline or SQL.
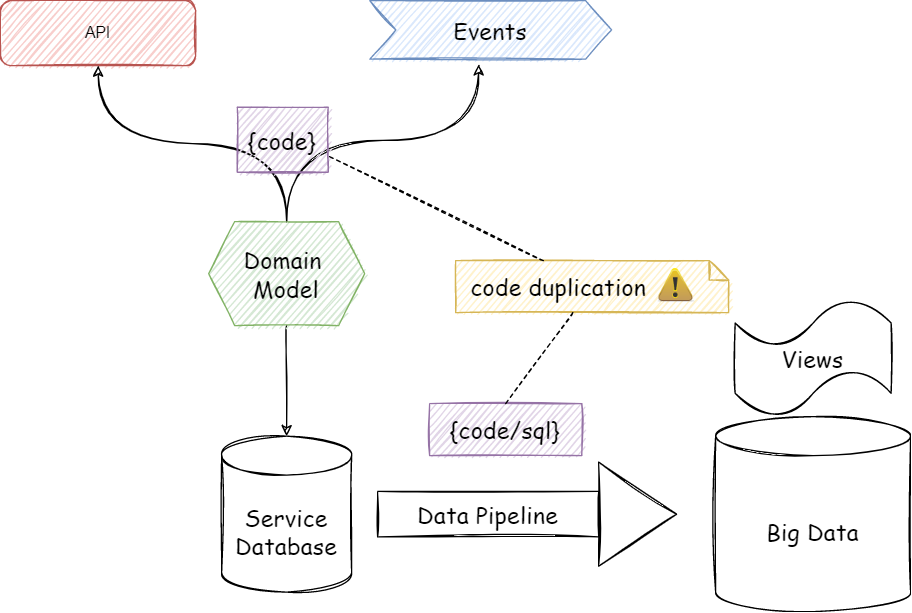
I will first discuss how duplication can be avoided in the APIs and Events, then we will see how we can publish data products in the data mesh architecture.
APIs and Resource Model
An API is typically the primary and frequently the initial interface for a system. When it comes to the API designs, there are mainly two options:
– RPC – Remote Procedure Calls / Customer Methods
– Resource (Entity) Oriented (e.g. REST).
While RPC has its advantages, REST, the mainstream resource-oriented pattern is enjoying a wider adoption mainly because it is easy to build and implement. Once you understand the basics of resource and HTTP verbs, it is pretty intuitive to integrate from the consumer side. There is a really good post on the Google blogs (https://cloud.google.com/blog/products/api-management/understanding-grpc-openapi-and-rest-and-when-to-use-them) that compares the two and suggests how a hybrid approach can give you the best of both worlds. There is an exhaustive guide from Google on defining the resource-oriented APIs in gRPC (https://google.aip.dev/)
The key challenge in resource-oriented designs is resource modeling. The common trap is to mix up the domain model with the resource model. Most of the time you will find that the resource model closely reflects the domain model but the devil is in the detail. We cannot simply allow the HTTP verbs as CRUD operations on our domain model. There is an excellent post on the Thoughtworks blog that unpacks the key challenges and suggests some alternative approaches: https://www.thoughtworks.com/en-au/insights/blog/rest-api-design-resource-modeling
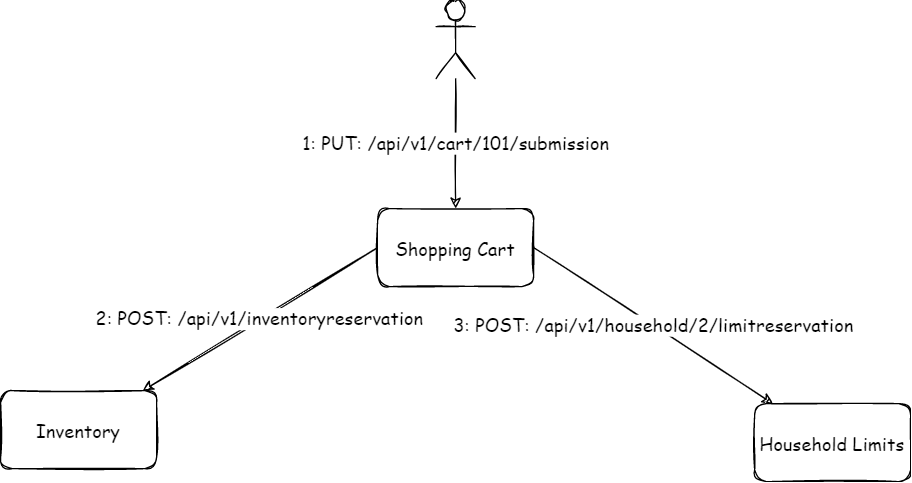
I will take an example of the shopping cart domain model to explain the problem.

In this domain model, we have “cart” as a root entity of the shopping cart aggregate. Adding any items to the shopping cart is an operation on the aggregate and the aggregate will run validations based on the business invariants and ensure the integrity of the aggregate before adding the item to the cart. But we may not want to expose our domain model as is to the external world. So we define this resource model as a layer of abstraction. There are different forces at play when creating an interface versus designing our domain model (integration, abstraction vs business invariants, model integrity). As an example, we may only allow access via functions on the aggregate instead of direct manipulation of the entities. However, in the RESTful resource model, the focus will be more on the conventions and rules of integrations based on REST principles:
HTTP POST: /api/v1/cart/101/items -> cart.addItem(cartId, productCode, quantity)
HTTP DELETE: /api/v1/cart/101/items/i100 -> cart.removeItem(cartId, itemId)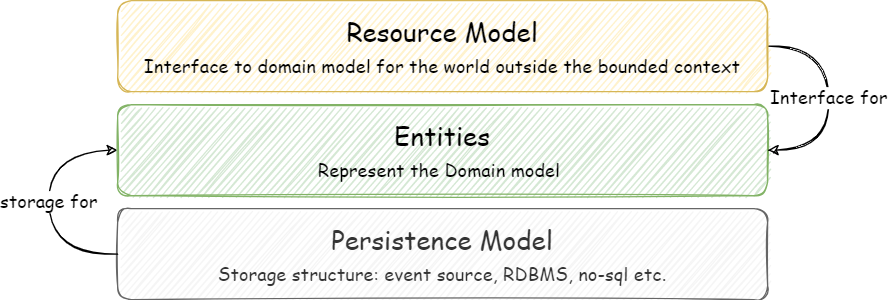
However, some actions will be hard to map with domain model actions using the CRUD (create, read, update, and delete) operations. Especially where it will result in a complex workflow. Let’s take the example of submitting the cart. Here, the business has some rules around enforcing a limit per household for certain products (toilet papers were one such item during covid lockdowns).
Now, the cart submission action needs to ensure that it reserves the limit before allowing the successful submission. There can be some other validations or side effects of the cart submission. So just a basic update (PATCH) to cart resource won’t be sufficient:
HTTP PATCH /api/v1/cart/101
Body: [
{
"op": "replace",
"path": "/status",
"value": "Submitted"
}
],The above approach has a few issues. In our example, we need the cart submission to:
- reserve the household limit,
- add to the wish list when it could not reserve the limit
- possibly reserve the inventory
The handler of these requests would require complex logic to work out the right combinations of fields and their values (submit vs clear) to trigger the corresponding domain operation. What if there are multiple fields, Can we allow the combination of the fields? What values are the client allowed to override? How to handle the race condition?
Instead, as the author of ThoughtWorks post recommends, we can design the process as a resource or leave it to the client to know the next step in the process.
Option 1:
HTTP PUT /api/v1/cart/101/submission
OR
Option 2:
HTTP POST /api/v1/order
BODY: { cartId: 101, .... }Though Option 2 in the above snippet can work but it is a bit problematic, what if there are some other validations required in the cart to make sure it is ready to be submitted. For Option 1, we can either return a redirect response (303) to the order or the cart resource. Submission resources do not have to map to any underlying domain model entity or we may not even persist it in our DB.
In case we are dealing with a long-running process, we may introduce the process as a first-class concept (i.e. entity) of our domain model e.g. User onboarding, where onboarding can be a resource in addition to the resource that gets created as a result i.e. User.
Events and Resource Model
So far we have looked into how our API resource model maps to our underlying domain model. Before we dig into how to model the events, let’s understand what events we will be producing and what are the key factors to consider.
Events are the way to broadcast an activity or a change in an aggregate of a bounded context that other systems/aggregates may be interested in. Events carry data payload along with some metadata such as the business definition of the event and subject, time, sequence, etc.
What Events to publish?
Let’s unpack the cart submission (checkout) process further to understand how events fit into it. We have to be very careful about choosing our events, it is easy to confuse commands with events. Even though it may appear we are using events but sometimes it is targeted asynchronous requests and responses (e.g. Cart Submit Requested). Events do not target a particular consumer or have an expectation on the consumer to do something about it. Please read my post on event vs commands for a detailed comparison.
Event Resource Identification and Workflows
The workflow or the process will reflect on what additional resources we create in addition to the resources created as a result, similar to the operation/process based APIs.
With Choreography
An event-driven based flow for the checkout process following a basic choreography pattern may look something like this:
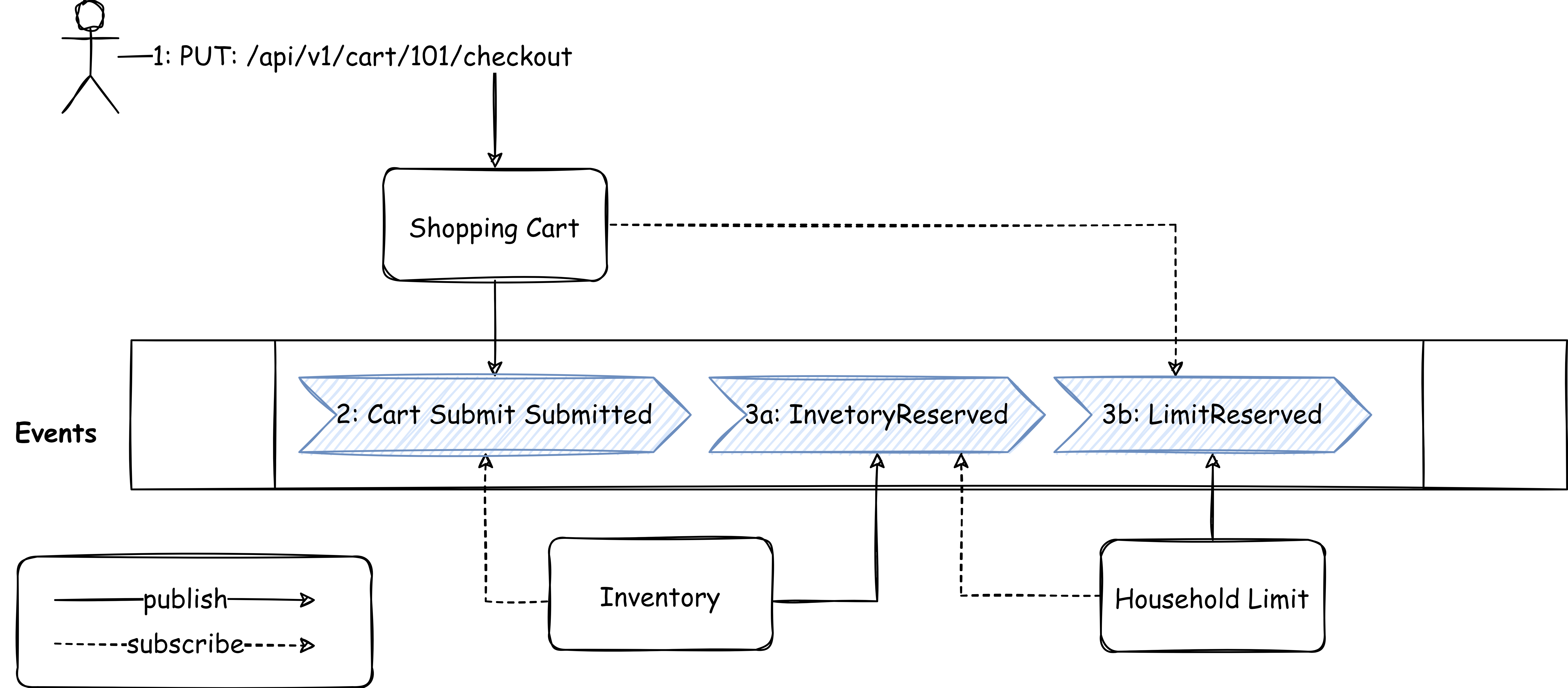
The very first message (i.e. Cart Submit Requested) can be argued if it is actually an event or a command disguised as an event. Going into that detail, sometimes give you insight into missing concept (aggregate) or incorrect boundaries.
What if the inventory reservation fails or the household limit exceeds? We can create a resource (checkout or order) to track the progress with a status attribute (like a state machine) based on the events received from inventory and household limit systems.
These multistep workflows are generally implemented as sagas which have mainly two flavors i.e. choreography or orchestration. There is a great post by Bernd Rücker comparing both patterns and suggesting a hybrid approach makes the best use of both worlds:https://www.infoq.com/articles/events-workflow-automation/ “Overall choreography and local orchestration”.
With Orchestration
Similar to the process/operation resource, we can nominate a checkout/order service that coordinates by sending commands to all the systems and waiting for the events from those systems. It maintains the checkout/order resource as it receives more events. This common service also takes care of any rollbacks e.g. if checkout failed after the limit was reserved, it will issue a command to the household limit system to release the limit.
Events for side effects only
Some flows are inherently complex and long-running, but sometimes the complexity is not from the business domain but how we have structured our models. Choosing events to suit a technical implementation is not always the best way to do things. Instead, events should be driven off the business flow. A really good way to identify events is by running workshops like event storming. I have written another blog post with a similar example to discuss this in detail.
It all depends on how the responsibilities are distributed in the systems. This is mainly driven by which part of the organisation is responsible for ensuring that particular action happens. Based on that we can distinguish the integral parts of the process from the side effects. Another way to look at is the consistency level, integral parts of the process are the changes that need to be strongly consistent with the process but side effects can be eventually consistent.
Not everything has to be a direct responsibility of the cart domain model. It will all depend on which business domain demands a particular action. If reserving the inventory is a prerequisite of cart submission, teams can negotiate and ask the inventory team to reserve the household limit as well. But again, it will depend on whose requirement is it e.g. sales or inventory.
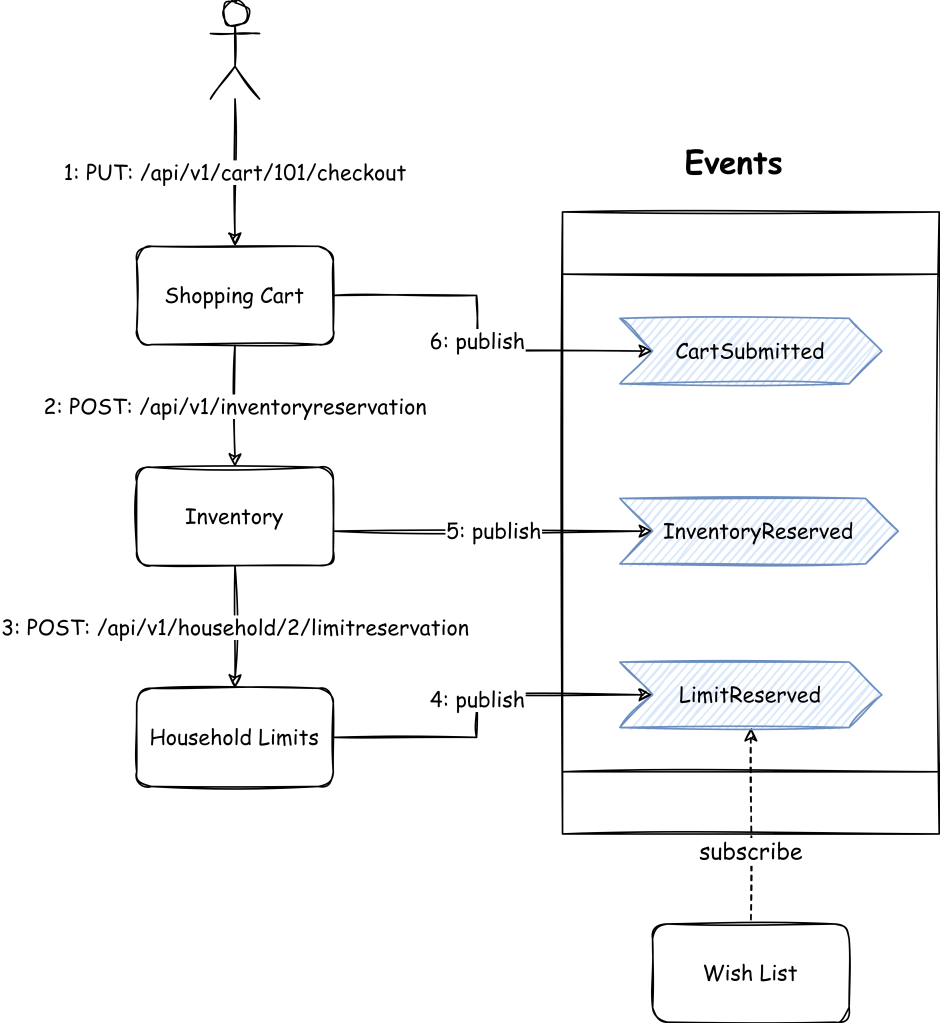
In case the business is happy with overbooking (i.e. compensating or apologising for the missing item in the cart), reserving inventory would just be a side-effect that does not have to be an integral part of the cart submission process. That means we are not allowed to process the cart without reserving the household limit, but the wish list and inventory can happen outside of the process life cycle. These side effects can be driven by event-driven integration.
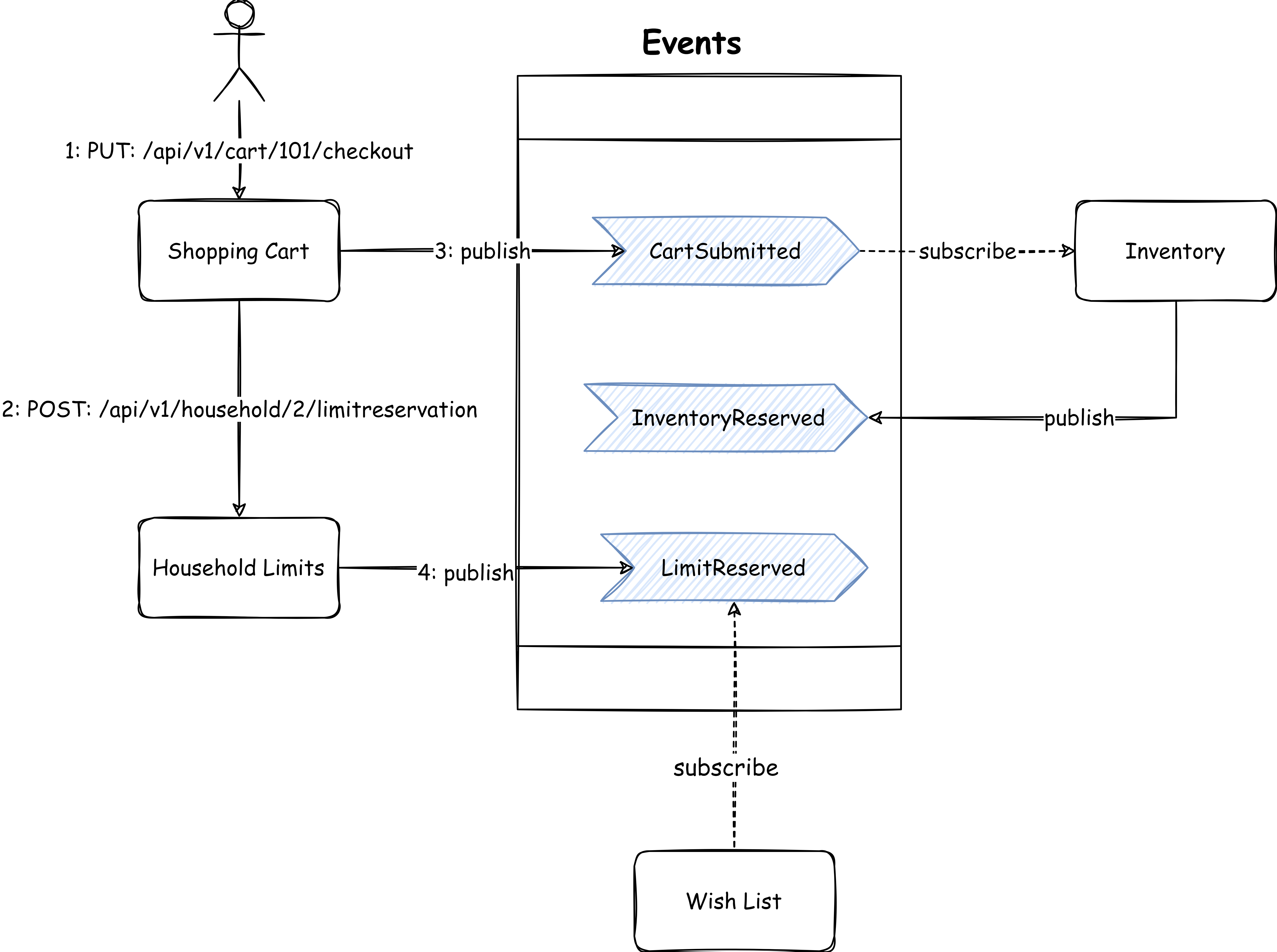
This simplifies the flow, cart submission only ensures that the household limit is reserved. It can be further simplified by making the limit reservation a side-effect as well. But the eventual consistent state can leave the window open where simultaneous requests can order more than the reserved limit. This actually depends on how strictly the business wants to implement this condition and stop any misuse.
As detailed in the above example, there are various factors that influence what resources we have and what events we need. Now the question is what goes into the events we produce.
Resource Model
As I have explained in the Events on the Outside vs Events on the Inside post, events that are broadcasted outside of the bounded context are sort of integration events so they inherit Data On the Outside characteristics. In a nutshell, they should carry a complete state or have enough information to retrieve the point-in-time state from the source. In another post, I explain that the event content should represent its parent aggregate. There can be multiple ways we can reflect our aggregate, it can be our domain model? or define a separate model for events? But we have already noticed that we use the resources model to represent our domain model via APIs. Why can’t we use the resource model in the events as well?
As noted earlier, the difference between the entity in the domain model and the resource is that resource is an external interface of the entity. It may hide, mask or add attributes driven from other attributes. This is the contract with the world outside the bounded context. If we can share the domain model state in the shape of the resource model via APIs, we can do the same when sharing the point-in-time state in events.
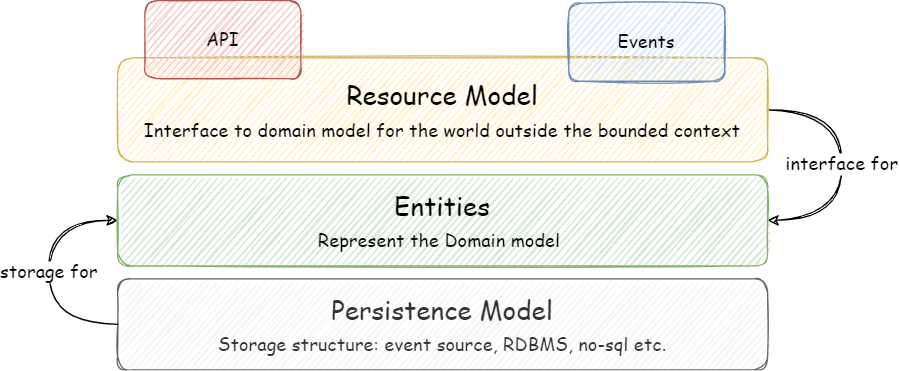
In the example we are following, our aggregate root entity is “cart” which we will represent as a cart resource. So this cart resource can be shared via API in HTTP Get and for any change, the same resource can be published in the event body
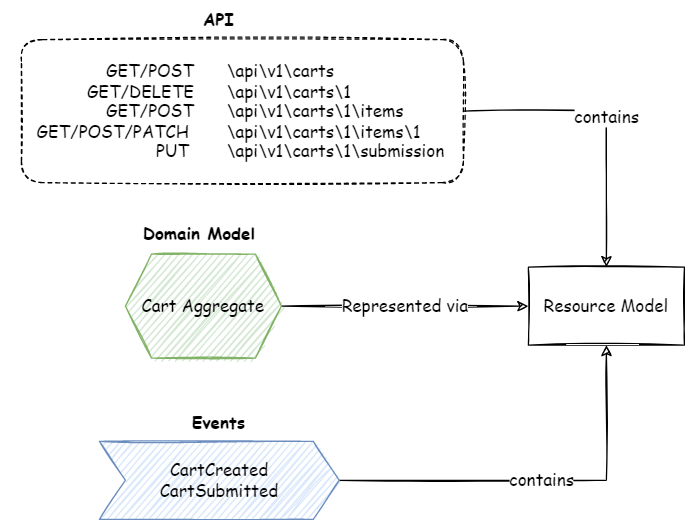
Kappa into Data-Mesh
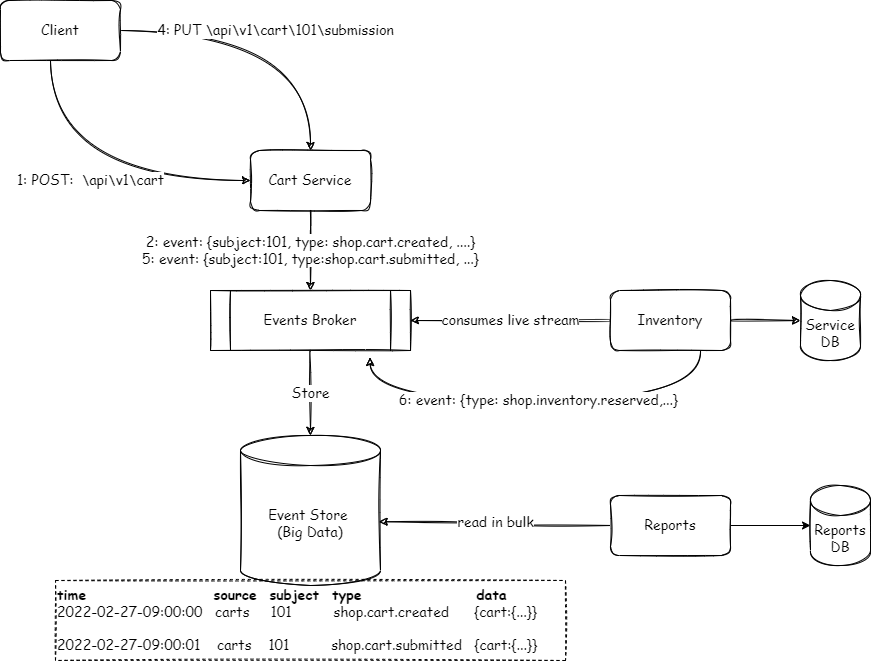
The key concept of the kappa architecture is that it advocates the use of a single source for both streaming and batch processing. In other words, instead of a separate extraction of data (i.e. ETL), we will store event streams to cater to the bulk/batch processing. There is a really good post on confluent: https://www.oreilly.com/radar/questioning-the-lambda-architecture/
Depending on the available infrastructure, you may have the event broker and event store as one or two different components. For simplicity’s sake, I am showing it as two different components in the following diagram. The same stream of events will be consumed by the real-time consumer as well for batch scenarios like reporting. Reports in this case will be like living documents.

There are a few things to unpack this. There are going to be many different producers each with its own schema. So we need some standard envelope with common metadata fields to allow some generic queries at a high level on the big data store. There are a couple of standard specifications available (such as AsyncAPI and CloudEvents) that allow us to specify the metadata in a standardised way. For instance, with CloudEvents you can use:
- Source (the system that produced the event)
- Subject (e.g. resource id)
- Type (type of the event e.g. shop.cart.submitted)
cart created:
{time:2022-02-27-09:00:00, source: carts, subject: 101, type:shop.cart.created, data:{}}
cart submitted:
{time:2022-02-27-09:00:01, source: carts, subject:101, type: shop.cart.submitted, data:{}}Generally, this type of data is persisted on a store that allows flexible schema i.e. No-SQL. These databases allow different types of query mechanisms. For readability, I will show the SQL syntax to show some basic queries. The actual usage of these data stores is going to be analytics and reporting, which will require more complex queries.
// get cart events for cart 101
select * from events where subject=101
// get latest state of the cart
select top 1 * from events where subject=101 orderby time desc
// get all shoping carts created on 27 Feb 2022
select * from events
where time between '2022-02-27:00:00:00' and '2022-02-27:23:59" This solves the problem at the generic level, but how about processing the data within the event. Because of the “Events on the outside” thinking and publishing complete resources with every change, our event store will be a time-series database for the resource.
The following examples represent two events on the cart but both carry identical schema but with different values. This is the same schema that you will get if you request HTTP GET: /api/carts/101/
cart created:
{time:2022-02-27-09:00:00, source: carts, subject: 101, type:shop.cart.created, data:{cartcreated: {cart:{id:101, status:created, customer:c1,items:[]}}}
cart submitted:
{time:2022-02-27-09:00:01, source: carts, subject:101, type: shop.cart.submitted, data: {cartsubmited: {cart:{id:101, status: submitted, customer:c1, items: [{item:201, quantity: 2, productId: p1}, ....]}}}Based on the above data, we can have a targetted view for each resource type but we won’t have to go to the level of each event type because all events for the aggregate will be carrying the same resource definition.
This design should work for the majority of the use cases, however, like every solution or pattern, there are always exceptions that need special handling. Some events or resources may not have a clear one-to-one mapping with aggregates.
Let’s assume a system that consumes signals from millions of devices and for each device it finds the median of hourly windows and publishes the value. We also have threshold criteria for these signals determined by the Machine Learning (ML) model. Instead of spraying the logic everywhere to correlate the signal and the threshold criteria, the service team could decide to combine the two in the same event.
{time:..., source: deviceMonitoring, subjec.t:D101, type: monitor.device.signalProcessed, data: {signal:{value:30.2, threshold:{criteria1:28, criteria2:35} }}In the world of machine learning-based algorithms, there can always be refinements in the model that would result in a different conclusion for the same data. Now if based on a new discovery in the observations, the ML model believes the threshold it used was higher than what it should be. The question that arises in these cases is if it impacts the new data only or historical data as well? In case one of the use cases requires data of last week should be reprocessed then we will have to publish the events for all the devices for last week. Depending on the number of devices the number of events to republish could be quite high (potentially millions). One alternative is to extract the threshold into a separate resource and just emit the ML model version with it. This will require the consumer to join the dots.
{time:..., source: MLModel, subjec.t:D101, type: ml.model.remodelled, data: {model:{id:M01, version: v01, criteria1:28}
{time:..., source: deviceMonitoring, subjec.t:D101, type: monitor.device.signalProcessed, data: {signal:{value:30.2, model:{id:m01, version: v01}}}
There is no right or wrong answer here, it will all depend on what forces are at play and which ones are considered more important by the business.
Conclusion
Defining the resource model as an abstraction on top of the entity model provides a well-defined contract that can be used to represent your data product in multiple dimensions (API, Events, and Big Data). However, we should not strictly restrict our systems to this model but also allow for the use cases where the alignment between various facades of our data product is harder to achieve. But if the majority of models are aligned, we have a lesser number of contracts to support the exceptions.

Leave a comment