In real-world monoliths, code of a single bounded context is spread across many dimensions. Extracting that code may require significant refactorings. It is rare to get an opportunity to refactor as a project of its own (in fact I do not believe that it is the best approach). So we try to do refactoring as a by-product of a business feature without blocking the delivery. Risks of relying on these occasional episodes of refactoring may make the decoupling journey too long to be effective. It will also require a very disciplined and coordinated approach amongst whoever is going to touch the code (too many cooks spoil the broth).
From my experience so far on decoupling monoliths, I believe the following are important considerations for extracting a bounded context:
- Delivery must not depend on future refactorings. They may not happen.
- Smaller incremental deliveries over big bang. So we do not block business features.
- Minimise changes in the existing code. Limit your investment on code you are planning to retire.
In another post, I wrote how to decouple a monolith based on Entity Framework or similar ORM. That is good when you want to extract the code and the schema as it is. But sometimes you want to redefine the model based on the deeper understanding of the domain you acquired by developing/maintaining this system for years.
It is not always easy to cut out a part of the database. Once a table/field has survived in the database for some time, its usages would be leaked to many places. These usages are not always easily detectable and often expensive to replace. A strangler pattern is a quite reasonable approach for decoupling and it can be implemented in many ways.
Once we have identified the bounded context, we would like to remove all its traces from the monolith and create a new system. But that won’t be iterative development. Instead, we can identify the smallest part of the bounded context to write in the new service. It is better to be something that you have to change anyway for a business feature delivery.
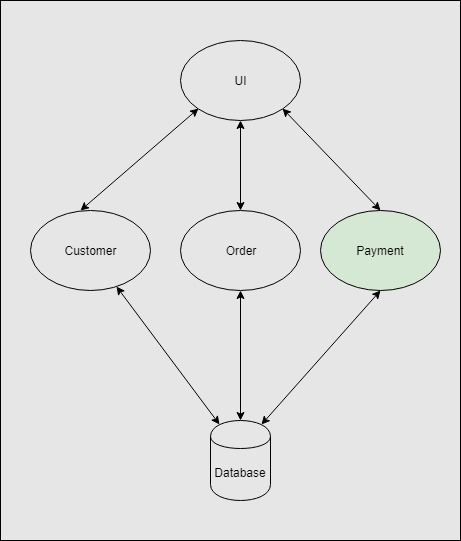
Let’s assume we are extracting the payment system from an e-commerce monolithic system to its own microservice.
The new system will have its own Database (documentDB, SQL Server or any other suitable database). We will redirect all the clients with the write operation (put/post/delete requests in HTTP terminology) to the new system. If possible we should try to read the requests as well.
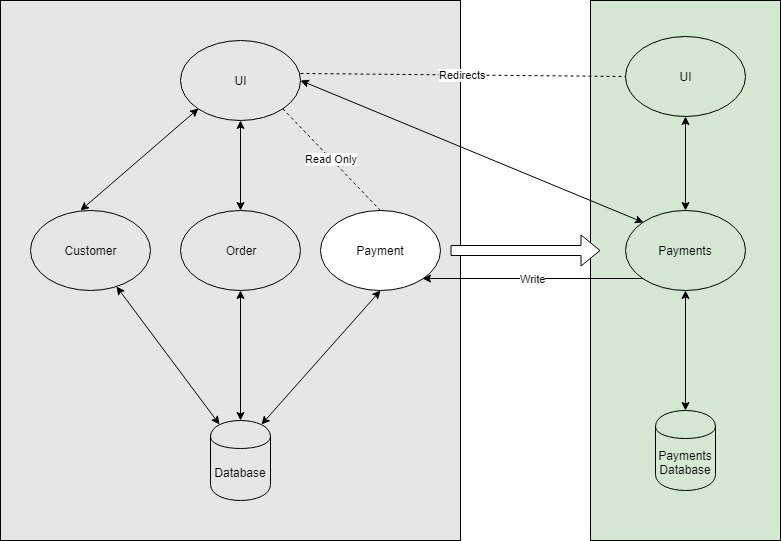
All the write operations will be directed to the new service. The new service will keep the old database up to date to support any sort of current dependencies on the existing systems i.e. foreign keys, query joins and reports etc. This saves us from a major refactoring, instead allows us to focus on the new service only. This is a simpler implementation, but it is a good start and you can iterate upon it from here.
The new service being dependant on the old code is not clean. The next iteration would be to remove this dependency and save the new service from any corruption that old service may introduce.

Here we have introduced an adaptor to act as an anti-corruption layer. The new service will emit the events from the business processes and the adaptor will listen to those events and perform the operation in the older world.
From this exercise, we get a very useful by-product in the form of events. Events can be subscribed by other systems and we can gradually steer the system towards event-driven architecture.
These two iterations will deliver us a new system while keeping the state hydrated in the legacy environment. Which would allow the legacy system to continue as if nothing has changed e.g. any queries/joins or reference to the data in the legacy environment will keep working. From here we can decide how we want to complete the extraction of the new system. We can either redirect these links/joins gradually to the new system (API calls etc.) or extract another sub system out of the monolith and eventually make all those links redundant anyway.

Leave a comment