Event sourcing gives us a few benefits such as in-built audit logs, replay/rebuilds, multiple projections (read models), and non-blocking writes. There is always the other side of every benefit we enjoy in the architecture language – we call these trade-offs. One such trade-off to consider is eventual consistency vs strong consistency and in this post, I am going to focus on that.
In many use cases, strong consistency is non-negotiable and the system cannot afford to wait for the state to become consistent eventually. One such example is financial transactions, there are some business rules that do not allow any room for an inconsistent state even if it is only momentarily. But it is not always a binary choice – there are trade-offs that can be managed.
Example
Let’s assume that our business has come up with a hard rule: customers cannot buy more than the allowed daily limit per household of certain products. This is to avoid the toilet paper shortage saga that was all over the news during Covid lockdowns. Business has decided to put a hard limit of 3 toilet paper bags per household.

In a standard RDBMS schema, a common table can track the limit per household. The service will process the purchase within the same database transaction, we will read and write to the limit table. This will place a lock on the limits table, so customers from the same household should not be able to purchase the item above the set limit.

If the system tried to process the shopping carts of Mr. and Mrs. Smith at the same time, only one of them would be able to acquire the database lock.
While this will meet the business rule, it creates a problem on the other side. Database lock contentions are hard to investigate and could impact the performance adversely. Sometimes, it could also lead to deadlocks – DBAs nightmares. This is definitely the thing we would like to avoid where possible. In fact, this is one of the key aspects where Event Sourcing can help.
Applying Event Sourcing
In a nutshell, event sourcing is about persisting your state changes in a series of events using an append only log aka Event Store. To apply event sourcing, we will need an event store. Following is a schema for a very basic implementation that will be sufficient to help explain the purpose of this page:
| Column | Description |
| Event Id | Primary key (UUID) |
| Event Name | Event Name e.g. Limit_Reserved, Cart_Submitted |
| Subject | The ID of the entity that has changed. Generally, it is a root entity of the aggregate. https://www.dddcommunity.org/resources/ddd_terms/ This provides a logical partitioning key to the data in combination with Event Name(s). It will be a Household ID in this case. |
| Timestamp | When the event occurred |
| Body | Raw body of the event e.g. JSON |
| …. |
So whenever the system processes a shopping cart, it will call the “Household Limits” service to reserve the limit. Since the concept is around households, the service will use it as a subject to partition the events by household IDs. For every successful request, it will append a new event called “Limit_Reserved” into the event store with the Household_ID as subject.
When a request arrives, the service will first load all the pre-existing events for the household and create a projection of the remaining limit. If the new request is below the remaining threshold, it will generate a new event called “Limit Reserved” and then store it in the event store table.
In the diagram below, there are 3 states of the projections, one is the initial state, indicating the remaining limit for the Smiths’ household is 3. Then after Mrs. Smith’s cart is processed, it will go down to 1, and then when Mr. Smith tries to process it, it will be rejected because the remaining limit is below the requested.
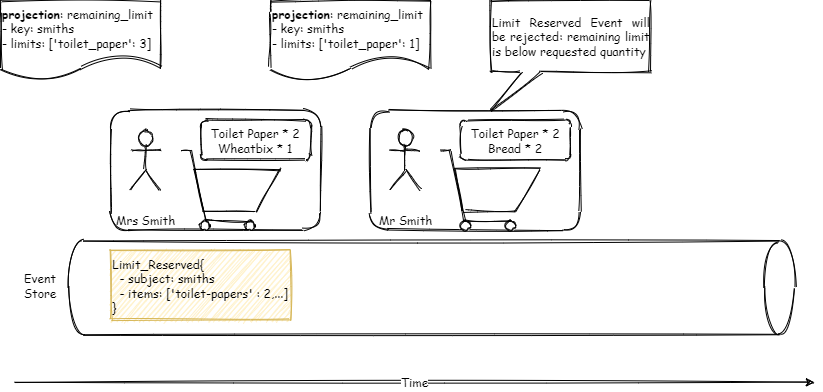
The Event Store is an append-only log, so there won’t be any contention in updating the same field. Both writes will be separate events inserted into the database. But what if they both try to process at the same time, how do we ensure consistency between two independent processes sharing the database. If not implemented correctly, in the above example Mr. and Mrs. Smith may be able to purchase the toilet papers more than the daily threshold. The following example depicts that problem:

To an extent, it can be managed by applying simple partitioning.
Divide and Rule
As mentioned before, events are logically organised into streams (subjects – generally the root entity of the aggregate: https://www.dddcommunity.org/resources/ddd_terms/). The service instances (node / VM etc.) that write to the event store will
- process requests sequentially e.g. running single-threaded or stateful
- have an affinity to a set of stream(s), so the events of a particular stream are always processed by the same instance.
With above setup, when Mr and Mrs Smith both tries to process their carts simultaneously , the requests will be processed sequentially and the problem will disappear (but not completely)
Altough it works, managing affinity brings its own bag of challenges such as load-balancing, hot-shards etc. Especially re-balancing to address hot shards or instance failures can open a small window of time where same stream may end up being processed by two different instances simultaneously.
Add Sequence Number
Here we will extend the event store schema by introducing sequence number to the events. This new column will also be part of the unique key (i.e. event name + subject + sequence number).
| Column | Description |
| Event Id | Primary key (UUID) |
| Event Name | Event Name e.g. Limit_Reserved, Cart_Submitted |
| Subject | The ID of the entity that has changed. Generally, it is a root entity of the aggregate. https://www.dddcommunity.org/resources/ddd_terms/ This provides a logical partitioning key to the data in combination with Event Name(s). It will be a Household ID in this case. |
| Sequence | Monotonically increasing number to reflect the sequence of the events for a subject |
| Timestamp | When the event occurred |
| Body | Raw body of the event e.g. JSON |
| …. |
In addition to the events body, the sequence number will be reflected in the projections generated from the events (both ad-hoc as well as persisted e.g. read models). The service will use the sequence number in projection to calculate the next sequence number:
new_event.sequence_number = projection.sequence_numer
Now if there are two separate processes arrived at the same time and read the same projection state, they both will create the new event with the same sequence number. But because of the unique constraint, only one of them would be allowed to be inserted into the table. The failed one will attempt again by recreating the projection and validating the request with recreated projection. The recreated projection will have a remaining limit reduced to 1 and sequence number to 1.

Conclusion
Event sourcing is an amazing pattern to persist your data but it brings its own package of trade-offs. In this post, I am just covering one such trade-off that from my personal experience at couple of occasions. In one case the team was caught off guard but fortunately in the other case I was able to flag it a bit early on to avoid any production issues. I hope teams considering event sourcing find this post useful.

Leave a comment